

Bigqueryでデータの整形から集計までのワークフローを組む場合、スケジュールクエリで行うことも多いと思います。
しかし、依存関係を定義できず、手動で時間をずらしながら登録するなど不便なこともあります。複雑なワークフローだと尚更です。
そういった課題を解決するサービス「Dataform」が、2020年12月にGoogle Clouodの傘下となりました。
このサービスは、SQLだけで依存関係の定義、ワークフローの構築、さらに単体テストまでを実装することができます。
本記事では、Dataformの概要や使い方について解説します。
目次
Dataformとは
概要
公式ドキュメントには、Dataformの定義として下記のように紹介されています。
Dataformは、BigQuery、Snowflake、Redshift、およびその他のデータウェアハウスのデータを管理するためのプラットフォームです。これは、データチームが生データを分析に使用できる新しいテーブルとビューに変換するデータパイプラインを構築するのに役立ちます。
Dataformは、ELT(Extract、Load、Transform)プロセスでTを実行します。ウェアハウス内のデータを抽出またはロードすることはありませんが、ウェアハウスに既にロードされているデータを変換することは非常に強力です。
データを活用する上で必要なT(Transform)、つまり変換・加工の部分をより簡単に行うことができるツールとなります。
データを扱いやすい形式に変換する、分析するために他のデータと組み合わせたテーブルを作成するといった変換・加工を、SQLのみで実現できます。プログラミングの知識は必要ありません。
少し前まではETL(Extract/Transform/Load)が主流でした。生データを取得(Extract)し、データを扱いやすいように変換・加工(Transform)してからテーブルに同期(Load)する方法です。
ETLではTの部分を主にプログラミングで実現します。GCPのサービスだとDataflowなどです。
ETLは、最終的に同期されるデータが整っていることがメリットですが、プログラミングの実装コストがかかるデメリットもあります。
一方ELT(Extract/Load/Transform)では、生データをテーブルに同期してから、扱いやすいテーブルに変換・加工します。
テーブルに落とし込んでしまえば、加工はSQLで行うことができます。また、生データをそのままの形でテーブルに保存しておくことで、変換・加工後との比較も容易です。
不具合があった場合も、生データと比較することで原因が特定しやすくなります。
料金体系
Dataform自体にはコストがかかりません。Dataformで利用するBigQuery、Snowflake、Redshiftの料金がかかります。
BigQueryだと、クエリ・データ保存量に対する料金となります。
Dataformの使い方
今回はBigQueryをベースにワークフローを作成する手順をご紹介します。
セットアップ
DataformのコンソールにGoogleアカウントでログインします。

サービスに同意し、Dataformのプロジェクトを作成します。


BigQueryと連携します。連携するGCPプロジェクト、BigQueryのロケーション、サービスアカウントを設定します。
※サービスアカウントに権限があれば、ここで設定したプロジェクト以外でもアクセスが可能



テーブル作成・ワークフロー作成・コード管理
DataformからBigQueryにテーブルを作成
SQLXファイルを作成します。SQLXとはSQLのオープンソースの拡張機能となります。SQLの実行のほか、データ定義の文書化やテストの実行が可能です。SQLX=変換ロジック+データ品質テスト+ドキュメントとなります。
左側のFILES>definitions>CREATE A DATASETを押し、ファイル名とテンプレートタイプを選択します。

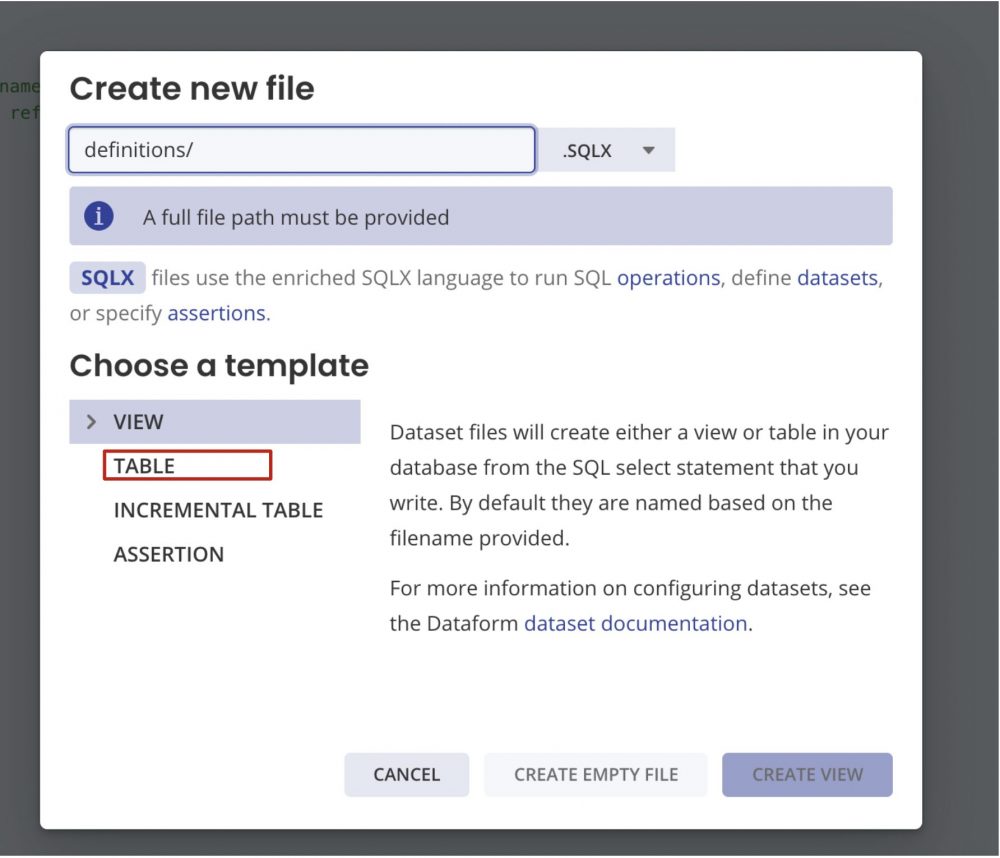
SQLXを書きます。
# データドキュメント
config {
type: "table",
description: "clearning table",
columns: {
id: "ID",
name: "NAME",
start_at: "開始日",
end_at: "終了日"
},
# データ品質テスト
assertions: {
uniqueKey: ["id"],
nonNull: ["id", "name"],
rowConditions: ["id <> 0"] # カスタム条件
}
}
# SQL
SELECT
id,
name,
start_at,
end_at
FROM
`project_id.dataset_id.table_name`右側のRUN ASSERTIONを押してテストを実行し、「Assertion passed」と出たら成功です。このように、assertionsで書いたテストがGUI上で実行できます。
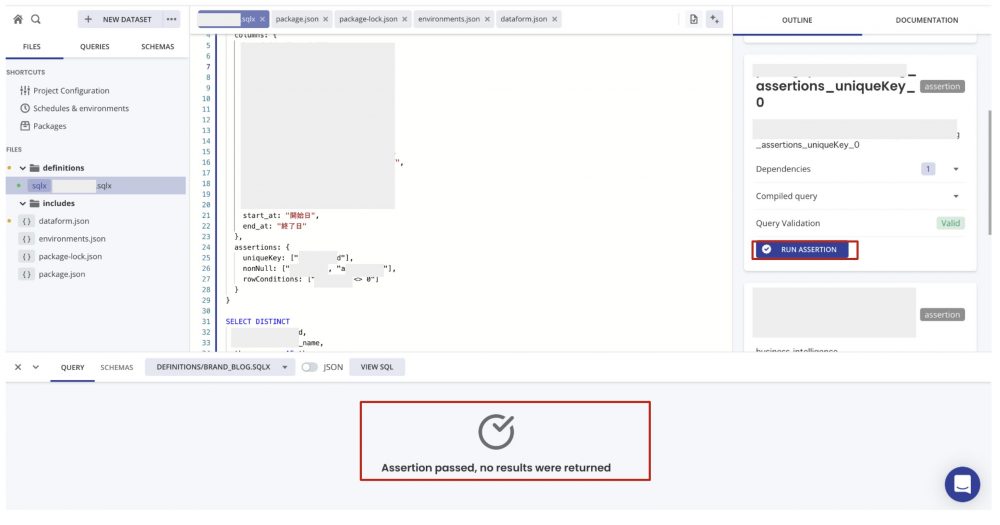
テストが通ったことを確認したら、右側のCREATE TABLEを押してテーブル作成を実行します。オプションで上書きするかどうかなども設定できます。

Dataformでワークフローを作成する
Aを実行したらBを実行する、といったように依存関係を定義する場合はref関数を利用します。Dataformで作成したファイルを${ref(“xxx”)}のように呼び出すことで、依存関係があると認識されます。
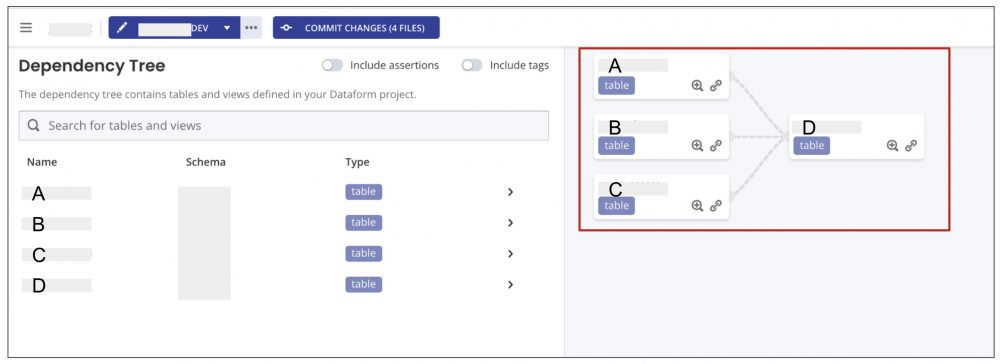
以下の例では、「A、B、Cというテーブルを作成してからDというテーブルを作成する」ワークフローを定義しています。
# D.sqlx
config {
type: "table",
description: "output table D",
}
SELECT
a.id,
b.name,
c.category
FROM
${ref("A")} AS a # A.sqlxとの依存関係
INNER JOIN
${ref("B")} AS b # B.sqlxとの依存関係
ON
a.id = b.id
LEFT JOIN
${ref("C")} AS c # C.sqlxとの依存関係
ON
a.id=c.id
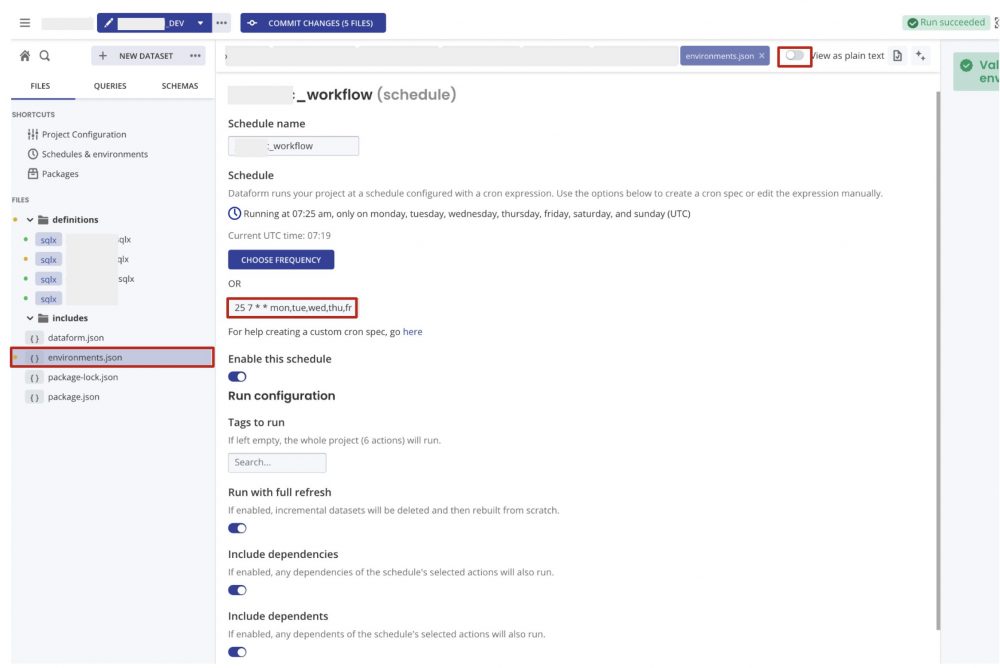
上記のワークフローをスケジューリングします。
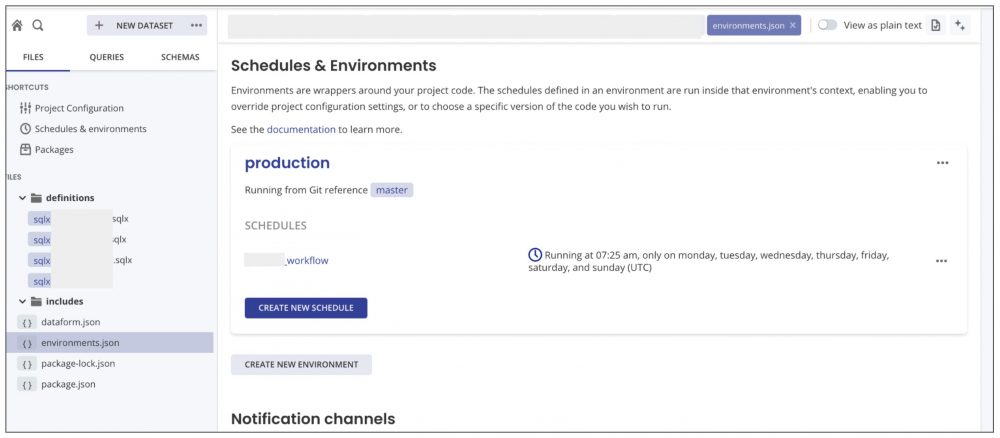
左側のFILES>includes>environments.jsonから、CREATE NEW SCHEDULEを押して設定します。上部のView as plain textを有効にすると、json形式で設定が可能です。
また、エラー時の通知設定もここから設定できます。
コード管理
SQLXの定義やスケジューリングの設定をGitHubで管理することができます。
公式ドキュメントには、GitHubアクションを利用してCI/CDを構成する方法も書かれています。
まとめ
Dataformの概要と使い方についてご紹介しました。
現時点でGCPコンソールと統合してはいませんが、近いうちに統合されると予想しています。
SQLで画面からワークフローが組めることはもちろん、データの定義やテストが簡単に書けることが何よりもメリットです。
この機会にぜひ利用してみてはいかがでしょうか。




