

Google Cloud の CDC(Change Data Capture)サービス Datastream が 2021年5月に発表されました。Oracle、MySQL の変更データキャプチャを Cloud Storage に反映することが可能です。
本記事では、Cloud SQL にたてた MySQL をデータソースとして、VPC ピアリングで Datastream と接続する方法をご紹介します。
目次
接続構成
Datastream とデータソースのネットワーク接続方法は3つあります。
- パブリック IP 接続
- フォワード SSH トンネル
- プライベート接続( VPC ピアリング)
Datastream と Cloud SQL をプライベート接続する場合、以下の構成をとります。
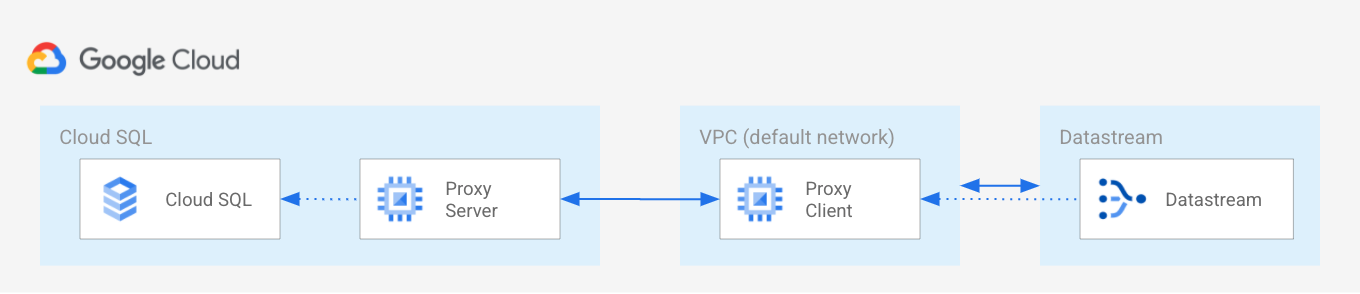
Datastream と Cloud SQL を直接 VPC で繋ぐことができないため、Cloud Auth プロキシを経由して接続する必要があります。
実装手順
接続構成を作成するために必要な手順は以下となります。
手順1. VPC とファイアウォールルールの作成
Datastream, Cloud SQL, Cloud Auth プロキシをインストールする Compute Engine で利用する VPC を作成します。
VPC ネットワーク画面から VPC ネットワークを作成へ進み、以下を入力します。
- 名前
- サブネット
カスタムモードで作成し、名前・リージョン・IPアドレス範囲を入力 - ファイアウォールルール
すべてにチェック

次に Cloud SQL で利用する内部 IP アドレス範囲の割り当てを作ります。
作成した VPC を選択してプライベートサービス接続へ遷移し、IP 範囲の割り当てを押下してカスタム IP を設定します。


続けてファイアウォールルールを作成します。
作成した VPC を選択してファイアウォールルールのタブへ遷移し、”ファイアウォール ルールを追加”を押下し、以下を設定して作成します。
- 名前
- ターゲットタグ
タグを作成 - 送信元 IPv4 範囲
手順5で Datastream の接続構成を作成するときと同じもの - プロトコルポート
3306


手順2.Compute Engine VM の作成
Cloud SQL Auth Proxy クライアントをインストールする VM を構築します。
Compute Engine の VM インスタンスから”インスタンスを作成”を押下し、以下の項目を設定します。他の項目はデフォルトのままにします。
- 名前
- リージョンとゾーン
デフォルトの us-central1 / us-central1-a - シリーズとマシンタイプ
コストを抑える場合はマシンタイプを最小にする - ブートディスク
デフォルトの Debian - ID と API へのアクセス > アクセススコープ
API ごとにアクセス権を設定を選択し、Cloud SQL を有効にする - ファイアウォール
すべてにチェック - ネットワーキング
ネットワークタグに手順1で作成したファイアウォール ルールのターゲットタグを付与する - ネットワークインターフェース
ネットワークを default から、VPCの作成で設定したネットワークに変更する


手順3.Cloud SQL の作成と証明書のダウンロード
Cloud SQL から”インスタンスを作成”を押下し、MySQL を選択します。
インスタンス ID、root ユーザーパスワードを設定し、インスタンスのカスタマイズに進みます。
接続の設定でプライベート IP にチェックをし、ネットワークと割り振られた IP を手順1で作成した VPC 、内部 IP 範囲を設定します。パグリック IP のチェックは外します。
他の項目はそのままにしてインスタンスを作成します。


作成したインスタンスから接続 > セキュリティへと遷移し、”クライアント証明書を作成”を押下して名前を設定し、証明書をダウンロードしておきます。Datastream の接続プロファイル作成時に利用します。


手順4.Cloud SQL Auth Proxy クライアントをインストールする
手順2で作成した VM に SSH し、Cloud SQL Auth Proxy クライアントをインストールします。
// 事前準備
$ sudo apt install wget
$ wget https://dev.mysql.com/get/mysql-apt-config_0.8.22-1_all.deb
$ sudo dpkg -i mysql-apt-config_0.8.22-1_all.deb
// <画面に遷移するので OK で進む>
$ sudo apt update
$ sudo apt install mysql-server
// <インストール画面に遷移するので OK で進む。rootユーザーPWも画面上で設定する。>
// Cloud SQL Auth Proxy クライアントをインストール & 起動する
$ wget https://dl.google.com/cloudsql/cloud_sql_proxy.linux.amd64 -O cloud_sql_proxy
$ chmod +x cloud_sql_proxy
// INSTANCE_CONNECTION_NAME は Cloud SQL の接続名<PROJECT_ID:リージョン:インスタンス名>に置き換える
$ ./cloud_sql_proxy -instances=INSTANCE_CONNECTION_NAME=tcp:0.0.0.0:3306
// 別ターミナルで以下を実行
// Cloud SQL Auth Proxy を起動したターミナルウィンドウで New connection for “<PROJECT_ID:リージョン:インスタンス名>” と出ていればOK
$ mysql -u root -p --host 127.0.0.1 --port 3306
// Datastrem で同期するデータベース、テーブルを作成しておく
mysql > CREATE DATABASE db_name;
mysql > CREATE TABLE db_name.db_table (id int, name varchar(10));
mysql > INSERT INTO db_name.db_table VALUES (1, "test");手順5.Datastreamのプライベート接続・接続プロファイルを作成する
Datastream の設定に入ります。
プライベート接続から VPC ピアリングを作成します。”構成を作成”を押下し、以下を設定します。
- 構成の名前と ID
- リージョン
デフォルトの us-central1 - 承認済み VPC ネットワーク
手順1で作成した VPC を設定 - IP アドレス範囲
手順1で作成したファイアウォールの送信元と同じ IP 範囲

続いて接続プロファイルを作成します。Datastream のソース元と出力先の2つを作成します。
“接続プロファイルの作成”を押下し、ソース元の MySQL を選択して以下を設定します。
接続設定の定義
- 接続プロファイルの名前と ID
- リージョン
デフォルトの us-central1 - 接続の詳細
“ホスト名または IP” に、手順2で作成した VM のプライベート IP を設定
Cloud SQL へ接続するユーザーとパスワードを設定
ソースへの接続を保護する
- 暗号化のタイプ
サーバークライアントに設定し、手順3でダウンロードした Cloud SQL のクライアント証明書をアップロード
接続方法の定義
- 接続方法
プライベート接続( VPC ピアリング)に設定 - プライベート接続構成
プライベート接続で作成したものを設定
上記を設定したら接続テストを実行し、通ったら保存します。


次に出力先の Cloud Storage の接続プロファイルを作成します。
- 接続プロファイルの名前と ID
- リージョン
デフォルトの us-central1 - バケット名
手順6.ストリームを作成する
最後にストリームの作成をします。
始める
- ストリームの名前と ID
- リージョン
デフォルトの us-central1 - ソースタイプ
MySQL
ソースの定義とテスト
- ソース接続プロファイル
手順5で作成した MySQL プロファイル
ソースの構成
- 含めるオブジェクト
“すべてのスキーマのすべてのテーブル”、”特定のスキーマとテーブル”、”カスタム手動定義”のいずれかを選択
宛先の定義
- 宛先接続プロファイル
手順5で作成した Cloud Storage プロファイル
宛先の構成
- ストリームのパス接頭辞
- 出力形式
確認と作成
“検証を実行”で確認が取れたら作成を押下



ストリームを開始すると、MySQL の変更データが Cloud Storage へ転送されます。


接続プロファイルのエラー対処法
MySQL の接続プロファイルのテストでエラー内容によっては、Datastream ⇄ VM ⇄ Cloud SQL(MySQL) のどこに原因があるかが分かりにくい場合があります。
We timed out trying to connect to the data source. Make sure that the hostname and port configuration is correct and that the data source is available.
このときに利用できるサービスがネットワークインテリジェンスです。接続テストで Datastream ⇄ VM、 VM ⇄ CloudSQL 間のネットワークをテストし、どこに問題があるかを突き止めることができます。

まとめ
Datastream と CloudSQL を VPC ピアリングで接続する手順をご紹介しました。
執筆時点での出力先は Cloud Storage のみで、BigQuery へ出力する場合は Dataflow を利用することになります。”Datastream to BigQuery” テンプレートが用意されており、こちらを用いるとノーコードで構築できます。
リアルタイム同期で鮮度の高いデータを保存することができ、これから広まっていくサービスではないでしょうか。
この記事が参考になれば幸いです!




